Rolling the Boulder Uphill: Rolling the Boulder Uphill: How Matter Approaches Parsing
One of a reading app’s most important jobs is converting unruly web pages and email newsletters into “reader view” — a beautiful, distraction-free interface optimized for reading.
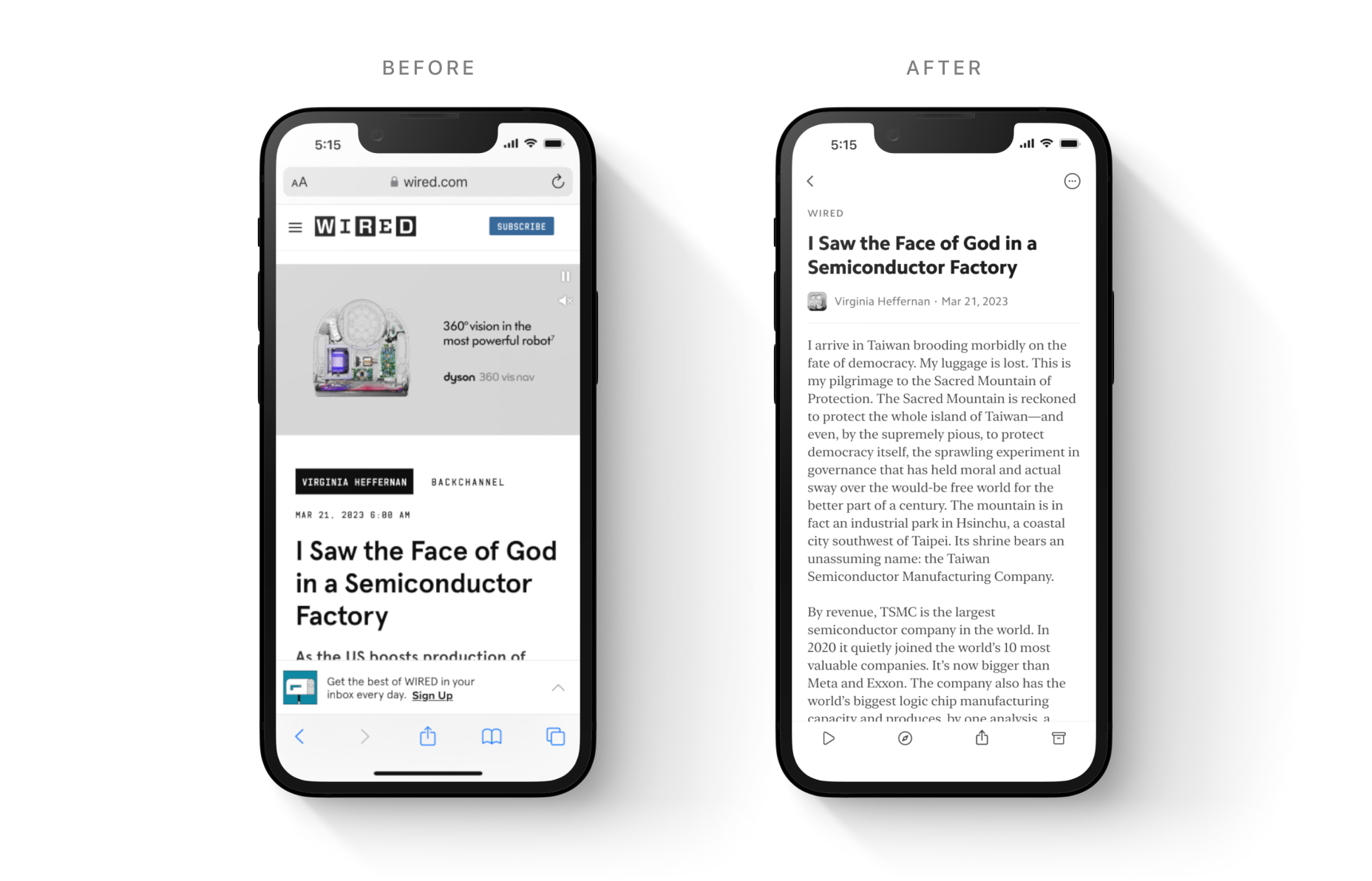
At Matter, the benefits of “reader view” are not merely cosmetic. They include critical functionality like offline support, dark themes, accessibility, text-to-speech, progress tracking, and annotation.
As such, it’s important that we parse pages accurately.
(For those new to the term, “parsing” is the process by which we extract the important elements of content – title, author, date, body text, images, captions – and jettison the distractions and boilerplate, like ads, menus, promotions, and email forms.)
Parsing is a trickier problem than it might first appear.
The challenge comes from the near-infinite surface area of the web. In such an unconstrained environment, it’s tricky to “read” a web page like a human would. To separate real content from boilerplate, we use a variety of layered heuristics and techniques. And while getting the first 80-90% of accuracy is relatively easy, the last mile is dominated by edge cases that can be hard to solve programmatically.
On top of that, web publishing standards are constantly evolving, resulting in the parsing equivalent of “bit rot.” In order to maintain the highest standard of accuracy, we need sophisticated systems for monitoring and improving our parser.
How It Started
For our first couple years, parsing was primarily managed in an ad-hoc manner. We relied heavily on user feedback to identify issues. Any time a user reported an issue with a particular article, we received a Slack message.
At a regular cadence, we would triage this list and try to prioritize the issues based on our own perceived importance. We think of parsing bugs as having two dimensions: impact and severity.
Impact was primarily based on the name recognition of the publication. Sites like The New York Times, The New Yorker, or any of the Condé Nast publications were prioritized over smaller blogs and newsletters. We also looked for high leverage opportunities around publishing platforms. If one Substack had a parsing problem, they all do.
When considering severity, we looked at how much the parsed version of a page deviated from the hosted version. Missing content was always considered higher priority than improper formatting, for example.
With these two dimensions, we would make judgement calls about what parsing bugs were addressed first, second, and so on.
The problem is that the internet is a big place and our user base started growing rapidly. It wasn’t long before the bug reports outpaced our ability to keep up.
To make matters worse, we were becoming increasingly hesitant to update our parsing system. Tweaking any individual parsing parameter would ripple through the system and impact any new content coming into it.
There was a constant anxiety that fixing one parsing bug would introduce dozens of others across the universe of internet writing. We were facing a parsing hydra. Any single parsing issue resolved might be replaced by several more.
It became clear that we had outgrown our ad-hoc, support-driven parsing system.
Getting Proactive
Late last year, we set aside a chunk of engineering time to rethink our approach to parsing. We had a few goals:
- Parsing performance should be measurable.
- Priority should be quantitive instead of intuitive.
- Parsing performance should only improve.
- Performance should be automatically measured and tracked over time.
Scoring Performance
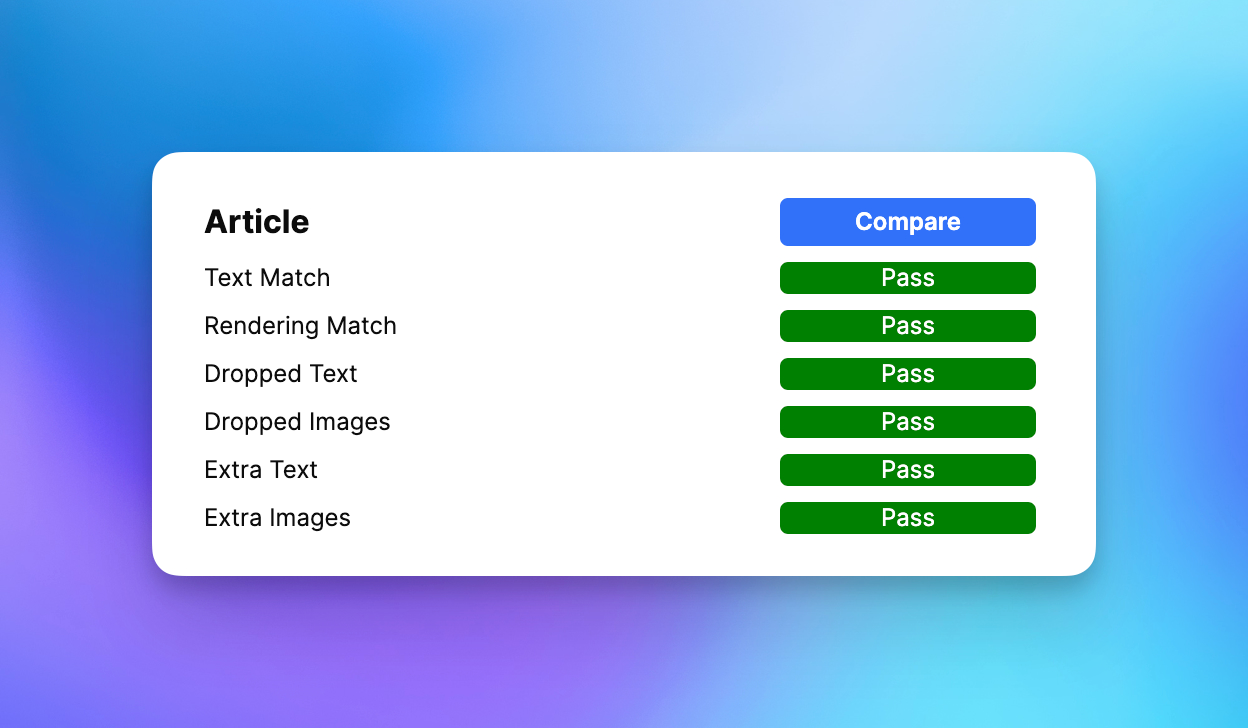
We began by developing a score card for ourselves. For any particular article, we needed to know how the parser performed when compared to the ideal output. Sourcing the ideal output requires judgement. Sometimes it’s not obvious whether a block should be included or how it should present in the Matter app. For that reason, our new tool relies on a human to curate an ideal test set over time. Every article that enters the test set is reviewed by an editor and touched up to be the ideal reading experience based on the source web page.
Once we had a reasonable starting point for our test set, we needed a quantitative way of comparing the output of our parser with the platonic ideal. While there are programmatic ways of comparing text outputs, we realized that not all errors are created equal. Metadata like the title, author, and publication date are more important to parse than any individual word within the article. And missing paragraphs within the article are a much larger problem than an incorrectly bolded word.
So we created a basic point system for scoring the parser output. If the parser outputs the right title, it gets 3 points. If the author is correct, the parser gets 2 points. If there’s missing text, the parser is penalized 5 points, and so on. A perfectly parsed article gets a total of 21 points.
Priority
We now had a way of scoring individual articles, but we still had only a cloudy notion of which problems should be fixed first. For example, does an improperly formatted section in a New York Times article have a larger impact than a missing paragraph from a niche blog?
To solve this problem, we incorporated popularity by pulling the number of Matter saves for each article in the test set. Just sorting by popularity was a big help. But we could answer the question above more specifically by multiplying the number of saves by the number of points deducted for any individual article.
So a New York Times article with a score of 20 out of 21 and saved 100 times has a priority of (21 - 20) * 100 = 100. A blog article with a score of 11 out of 21 and saved 5 times has a priority of (21 - 11) * 5 = 50. In this case, it makes sense for us to resolve the New York Times bug first.
We now had numbers for the impact and severity intuitions we started with.
Scoreboard
When looked at in aggregate, the priority scores for the test set give us a metric to track over time. We turned this into a basic percentage grade:
sum(priority score) / sum(max score * total saves) = % score
Not only did this give us a goal, it allowed us to make changes to the parser with confidence. If we made a change targeting a specific article, we could measure the change’s ripple effects by tracking the score.
We created an internal policy when making parser changes: the score never goes down. At worst, any particular change must maintain our current level of performance. At best, we should see an improvement. Combined with our prioritized list of fixes, we started ratcheting the parsing score up and to the right.
Automation
The final part of this overall project was to integrate parsing monitoring and improvement into our weekly product cadence. We want to expand our test set over time to cover an ever increasing surface area of the internet (or, at least, the parts of the internet that our users read) and to ensure our current performance doesn’t slip due to updates to the source web pages.
We expand our test set in two ways. First, every week we sample our popular articles and add a handful to the test set for review by our editor. Second, we automatically pipe all user bug reports to the test set for review. On a regular cadence our editor works through the backlog of new articles to review and creates the ideal output for each of them.
Ensuring continuing performance is a little more tricky. The internet changes constantly and we need to make sure we are keeping pace. For example, if the New Yorker introduces a newsletter form in the center of their articles, we want to be alerted to the change and update the parser accordingly. This requires refetching the article source to test against.
So we set up an automated testing schedule. Every Monday and Thursday morning, we refetch every test case’s webpage, parse the output, score it, and then report the aggregate scores back to our slack channel. Left unattended, the score will decline gradually over time, as changes to publishing and web standards cause regressions. But by monitoring and responding to these dips each week, we can continue to improve parser performance and overcome the drift of entropy.
The Final Product
All of this work is managed in a Retool dashboard that our engineering team monitors thanks to the Slack reminders.
Every full test run is tracked over time so we can monitor progress. Within each test run, every test case is presented in priority order. The articles with the most ground to gain appear at the top for us to triage.
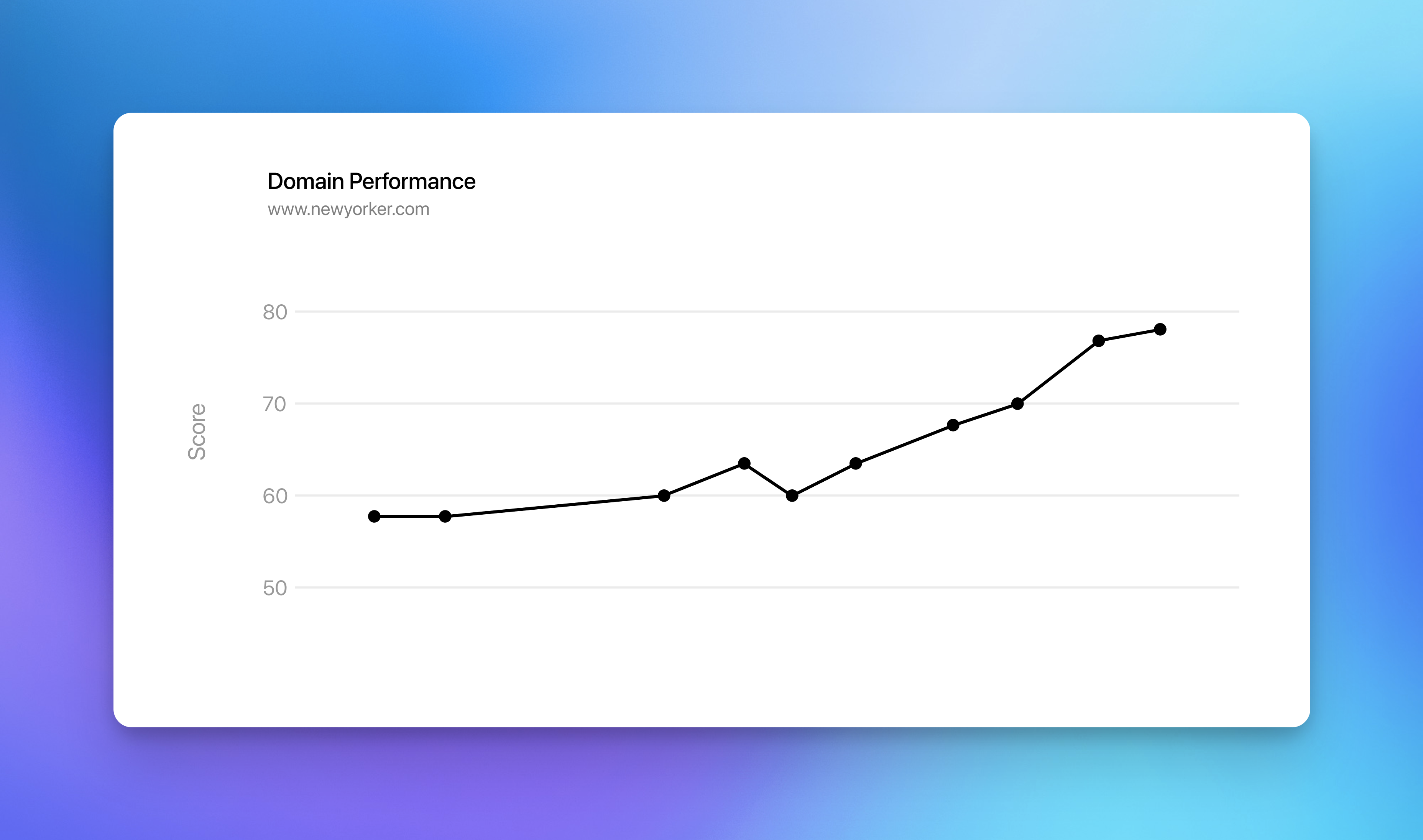
Since implementing this new monitoring system, we have improved our parsing across the board. We have seen continuous large improvements in our score as high impact parsing changes were released with confidence. But most importantly, our new automated system ensures we are continuously improving on the foundation of Matter.
A reading app is only as good as its parser, and ours is well tended to.